一个真实的外贸早晨:收件箱里的"翻译炸弹"
周二早上9点,做小家电出口的Lisa打开电脑,WhatsApp上美国客户Kevin发来一条消息:"Hey Lisa, checking on the order. Also attaching the updated spec sheet and some competitor comparison screenshots —— can you review and get back by noon your time?" 附件栏里躺着一个8MB的英文PDF规格书,以及五张产品对比页面的英文截图。
这不是Lisa第一次面对这种"翻译炸弹"——跨境外贸里的文档翻译从来不是"偶尔翻一页"的轻任务,而是每天高频出现的效率关卡。据Grand View Research 2025年机器翻译市场报告,全球企业在文档翻译上的年支出超过120亿美元,其中中小企业最头疼的不是翻译费用本身,而是"文件格式碎片化 + 紧急排期"导致的效率黑洞。一份PDF要译成中文审阅、五张截图里的关键参数要提取对比——如果Lisa全靠传统方式:先截图OCR、逐段粘贴到翻译工具、再手工排版还原,30分钟根本不够。
这篇文章复盘一个完整的工作流——从收到混合格式文件到拿出可用的中文版本,30分钟内全部搞定,而且不是靠"加班手速"。
第一步:分清"要精读的"和"要扫一眼的"——文档翻译的预处理决策
Lisa收到的是两类文件:一份需要逐字确认的规格书(合同附件性质),五张用于市场情报的竞品截图。前者对翻译准确度要求高——一个电压参数的误译可能导致整批货不合规;后者重在快速提取关键信息。
很多外贸人犯的第一个错误是"一视同仁"——把合同级别的PDF和仅供参考的截图用同一个流程处理。正确的做法是先做一次快速分级:
- 合规级:合同、规格书、认证文件——翻译后需要人工复核关键数字和条款
- 情报级:竞品截图、市场报告摘录、客户非正式反馈——快速提取关键信息即可
- 沟通级:客户问题截图、邮件附件说明——理解意图优先于逐字准确
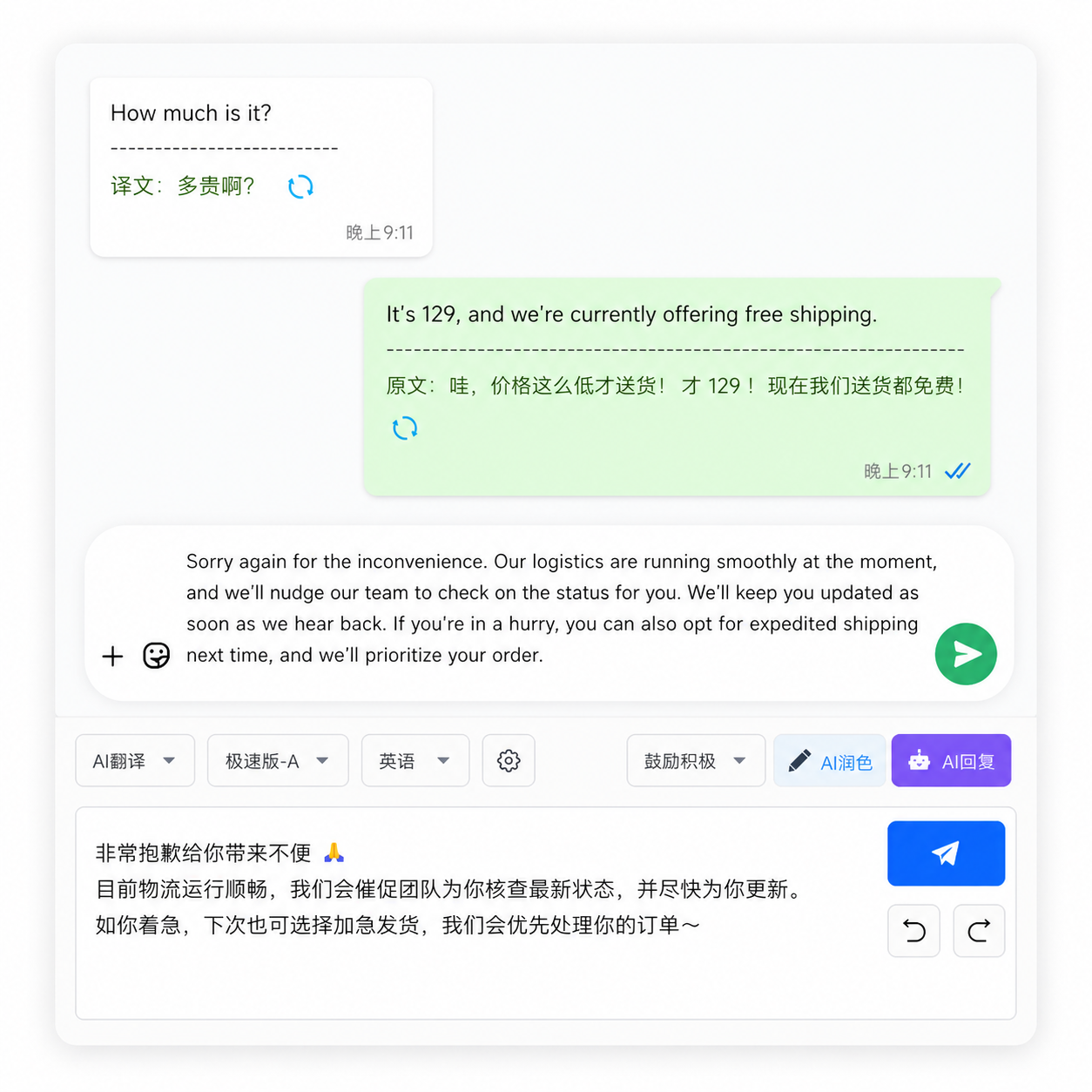
分级之后,Lisa的30分钟分配就清晰了:20分钟用于合规级的规格书翻译加复核,10分钟处理五张情报级截图。这种分级思维本身就是最高效的图片翻译前置策略——不是所有图片都需要逐字翻译,大部分只需要提取关键参数。
PDF规格书:为什么"复制粘贴到网页翻译"是最慢的做法?
Lisa第一次尝试是标准的"笨办法":打开PDF→全选→复制→打开浏览器→粘贴到在线工具→等待结果→复制回来→在Word里重新排版。三个问题立刻暴露:PDF里的表格格式全乱了,技术参数和数据错位;图片里的文字(例如产品尺寸标注、认证标志上的说明)根本选不中;整个流程至少15-20分钟,排版还原又花了10分钟。
更高效的做法是:OCR识别→结构化提取→批量翻译→关键字段人工复核。根据Slator 2024年语言行业市场报告,使用AI辅助工具进行文档翻译的企业,平均将处理时间缩短了62%,错误率降低了34%——关键不是"AI翻得比人准",而是"AI不会在复制粘贴时漏掉半页内容"。
五张英文截图怎么快速消化?图片翻译的两个路径
截图翻译比PDF更让人烦躁。文字嵌在图片里,传统的做法是盯着屏幕一行行手动翻译、在Excel里做对比表。五张竞品参数截图,Lisa以前要花40分钟才能整理出一个像样的表格。
现在有两条成熟路径:
路径A —— OCR识别加翻译加结构化输出:适合需要精确数据提取的场景。用OCR工具识别截图中的文字→机器翻译→将关键参数填入预设的对比表格模板。适合需要存档、需要后续引用的场景。
路径B —— 即时聊天内翻译:适合速度优先的场景。如果客户直接在聊天工具里发来截图问"how does this compare to our specs?",用OneChat一聊的内置翻译直接在聊天上下文里完成对比,不需要切换到其他工具。这种方式省去了"导出→OCR→翻译→导入"的中间环节,尤其适合高频次的跨境沟通中碎片化的小文件需求。
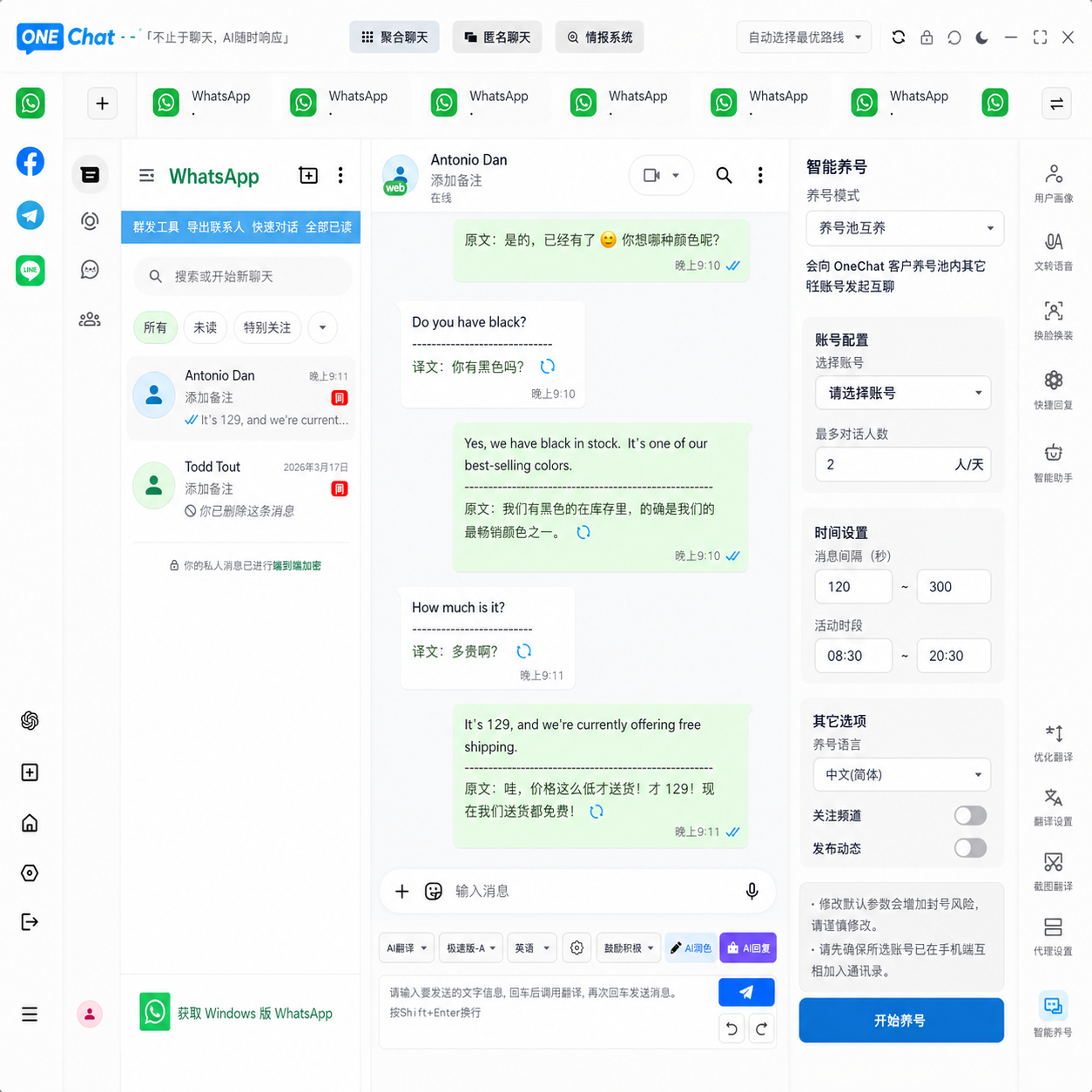
一次搞定的30分钟工作流(完整复盘)
Lisa第二天换了方法,完整流程如下:
| 时间 | 动作 | 工具/方法 | 产出 |
|---|---|---|---|
| 9:00-9:02 | 文件分级:识别PDF为合规级,截图为情报级 | 人工判断(30秒即可) | 优先级排序 |
| 9:02-9:10 | PDF规格书OCR加结构化翻译 | OCR加AI翻译工具 | 中文版规格书初稿 |
| 9:10-9:18 | 关键参数人工复核:电压、功率、认证标准号 | 逐项对照原文 | 确认无误的规格书 |
| 9:18-9:25 | 五张截图翻译加参数提取 | OCR加翻译加对比表模板 | 竞品对比表 |
| 9:25-9:30 | 回复客户:确认规格加竞品分析要点 | OneChat一聊直接回复 | 一条专业的客户回复 |
全程30分钟,比Lisa原来1小时以上的流程缩短了一半多。关键是省下了"复制粘贴排版本"和"手工做对比表"这两块最大的时间黑洞。
挑翻译工具看什么?三个不可跳过的评估维度
市面上的方案从免费到企业级都有,Lisa最后的标准是:
- 格式保真度:输入PDF→翻译→输出后表格还在、图片还在、排版不变形。很多免费工具在这一步就翻了——输出纯文本,格式全丢。这对PDF翻译场景尤其致命,因为商业文档的排版本身就是信息的一部分。
- 图片内文字识别能力:PDF里的嵌入式文字和独立截图都需要OCR。需要确认工具支持中英双语OCR,且对技术文档常见的无衬线字体有较好识别率。这直接决定了截图翻译功能的可用性——OCR不准,后面全白做。
- 工作流集成度:最好不跳出日常使用的聊天工具。在OneChat一聊里收到文件,直接在聊天窗口里看到翻译结果,比"下载→上传到翻译网站→下载译文→回传"高效得多。对于依赖高频跨境沟通的团队,这个集成度差异一天能省出半小时。
能不能放心把商业文件交给AI翻译?
这是外贸人问得最多的问题。答案不是"能"或"不能",而是:取决于文件的风险等级。
一份内部参考的竞品截图,AI完全够用——速度比人工快10倍,准确度对于"了解对方大致参数"这个目的绰绰有余。一份提交给海关的合规文件,AI作为初稿加人工复核才是正确姿势。据CSA Research 2023年全球翻译服务调研,采用"机器翻译加人工审校"模式的企业,翻译成本平均降低40%-60%,同时保持了专业级质量——核心是"把AI用在对的地方",而不是追求全自动。对于日常的文档翻译工作流来说,MTPE(机器翻译+人工编辑)是目前性价比最高的方案。
外贸人日常中,截图和PDF哪个更花时间?
很多人直觉以为是PDF——文件大、内容多。但Lisa三个月的个人时间记录显示了一个反直觉的结果:她花在处理图片类文件上的累计时间(每月约6小时)反而超过了PDF翻译(每月约4小时)。原因很简单——PDF有固定的处理流程,截图却是"高频次、碎片化"的。每次收到一张截图都意味着打断手头工作、切换到翻译模式、再切回来。这种"上下文切换成本"累积起来比做一份PDF翻译更高。
所以真正的效率提升不在于"把PDF翻得更快",而在于让截图翻译融入聊天工作流本身——在聊天工具里直接看到翻译结果,消除切换成本。这是提升跨境沟通效率最被低估的一步。
FAQ Schema
AI翻译能完全取代人工做商业文档吗?
不能,也不需要。合理的定位是替代翻译中重复、低价值的部分——格式转换、初稿生成、术语一致性检查——让人专注于需要判断力的环节:关键条款的措辞确认、文化适配、客户意图的解读。追求100%替代是错误的目标,把60%的重复劳动自动化才是务实的做法。
PDF里的表格翻译后格式会乱吗?
取决于你用的工具。专业文档翻译工具可以保留表格结构、合并单元格和基本格式;免费在线工具通常输出纯文本,表格变成一堆错位的文字。如果PDF里的表格是你的工作常态,花时间找一个支持表格保真输出的工具是值得的投资。
图片翻译和普通文档处理需要分开用两个工具吗?
不一定。一些综合性平台同时支持PDF和截图OCR翻译,但如果你已经在用OneChat一聊处理日常客户沟通,聊天窗口内的即时翻译可以覆盖大部分截图需求,正式的PDF文档则可以用专门工具处理——两条路径各有侧重,关键是不要为了一张截图就跳出工作流。
哪些类型的文件绝不能用纯机器翻译?
法律合同、医疗记录、专利文件、涉及金额数字的金融文件——这四类的误译后果太严重,建议采用MTPE模式:机器翻译出初稿,由有专业背景的人(或至少熟悉该领域术语的人)逐项审校。时间允许的话,找一位母语者做终审阅读是最稳妥的。
用AI工具翻译客户发来的文件,客户会介意吗?
大多数客户不会介意——他们关心的是你能否准确理解需求并快速响应,而不是你用了什么工具。就像客户不关心你是用Excel还是Google Sheets做报价单。但有一个例外:如果涉及保密协议或独家合作条款,建议告知客户你的翻译工具采用了本地存储而非云端处理,这反而体现专业度。
用OneChat一聊,客户发来的外语文档和截图直接在聊天窗口里完成翻译——日常的文档翻译和图片翻译都不再需要跳出聊天界面。 不再切换工具、不再复制粘贴、不再担心格式丢失。支持多平台聚合聊天 + AI实时翻译 + 本地数据存储,一个窗口管理所有跨境客户沟通。
免费体验 OneChat一聊