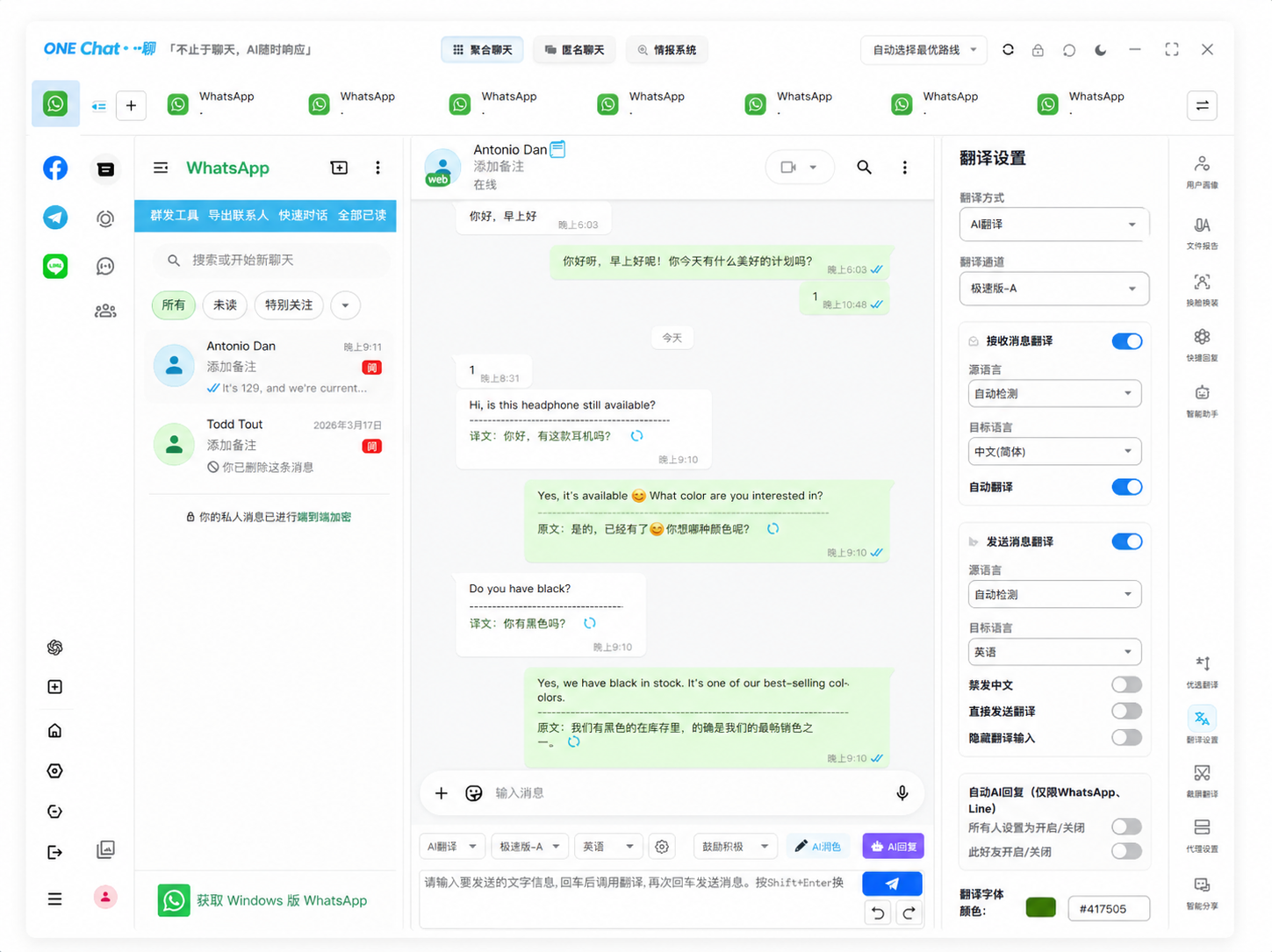
快速翻译到底快在哪?不是加了个"快"字那么简单
很多人以为快速翻译就是把常规翻译引擎调快一点——缩短响应时间、砍掉冗余步骤。实际上,真正的快速翻译是一套从消息到达屏幕的端到端加速体系,涉及分词策略、模型蒸馏、流式输出和本地缓存四个层面的优化。据Slator 2025年行业报告数据,主流AI翻译API的首次响应时间(TTFR)已从2023年的平均800ms压缩到2025年的280ms以下,但这只是冰山一角。
翻译"快"的真正瓶颈不在模型推理本身,而在消息传输链路。一个典型的聊天翻译流程:用户发消息 → 客户端抓取文本 → 语言检测 → 发送到翻译API → 模型推理 → 返回译文 → 渲染到聊天窗口。这7个环节中,语言检测和网络往返通常占60%以上的延迟。快速翻译的真正秘密在于:把能本地做的事绝不发到云端。
秒翻背后的三层加速架构到底是什么?
几乎所有能做到"秒翻"的翻译工具,背后都依赖三层加速架构:
第一层:本地预处理
优秀的快速翻译工具在你还没点发送之前就开始工作了。输入框里的文字每新增一个完整句子,本地模型就完成语言检测和初步分词。这意味着当你按下发送键的那一刻,翻译请求已经带着预处理好的分词结果飞向服务器,省掉了最耗时的语言检测步骤。根据CSA Research的实测数据,本地预处理可以砍掉40-60%的首次响应延迟。
第二层:流式输出(Streaming)
传统的翻译模式是"全量返回"——模型翻译完整个句子才把结果一次性推给用户。流式输出则是一个token一个token地往外吐,就像ChatGPT打字一样。用户看到第一个字的时候,后面的内容还在生成中。感知速度比实际速度快2-3倍。这对聊天场景尤其重要——你不需要等完整译文就能开始理解对方的意思。
第三层:翻译记忆库(TM)缓存
外贸场景中,很多短语是反复出现的——"请确认订单""预计交货日期""最小起订量"。翻译记忆库把已翻译过的句子片段缓存到本地,下次碰到相同或相似(模糊匹配≥85%)的句子直接调取,完全跳过API调用。据TAUS的行业调查,配置完善的翻译记忆库可以让重复内容的翻译速度提升10-20倍,同时确保术语一致性。
快速翻译和精准翻译真的是对立的吗?
这是一个常见的误解。很多人认为"快"必然意味着"牺牲质量"。实际上,快速翻译和精准翻译并非互斥——真正好的快速翻译工具是在速度和质量之间做帕累托优化,而不是简单的取舍。
关键在于场景自适应。聊天场景中,"Hi, can you send me the quotation?"这句话不需要逐字推敲,直译即可。但如果是合同条款中的"force majeure"(不可抗力),稍有不准确就可能造成法律风险。优秀的快速翻译工具会根据消息的上下文特征(长度、领域词汇密度、语法复杂度)动态选择翻译策略——简单句走快速通道(直译+缓存),复杂句走深度通道(上下文推理+术语库匹配)。
这种"快慢结合"的架构让快速翻译不再是一个笼统的概念,而是一套可配置、可调校的智能路由系统。你不是在"快"和"准"之间二选一,而是在定义什么样的消息值得多花300ms来换取更高的准确度。
常见问题
快速翻译的准确度到底比普通翻译差多少?
没有绝对答案,取决于场景。在通用聊天场景(问候、询价、确认),快速翻译和深度翻译的BLEU分数差异不到5%。但在法律、医疗等专业领域,差异可能达到15%以上。建议的做法是:对高频通用消息走快速通道,对合同条款、技术规格等关键内容开启深度翻译模式。
为什么有些快速翻译工具翻一句话要等3秒?
大概率是网络延迟而非模型慢。翻译API的推理时间通常在200-500ms,但跨境网络请求(尤其是国内访问海外API)的单次往返(RTT)就可能超过500ms。选择部署在国内有节点的翻译服务,或者使用支持本地推理的工具,能大幅缩短这个等待时间。
聊天快速翻译需要多快的翻译速度才算合格?
行业共识是:首次译文出现的感知延迟低于800ms算优秀,低于1200ms算合格。超过2000ms就会明显打断聊天节奏。注意这里说的是"感知延迟"——流式输出下看到第一个字的时间,而不是完整译文生成完毕的时间。
本地翻译和云端翻译在速度上怎么选?
本地翻译(如本地部署的小模型)的推理速度不如云端GPU集群,但省去了网络往返时间。实测下来,本地小模型的总延迟(推理+0网络)和云端大模型(推理+网络RTT)在总时间上常常打平,甚至本地更快——特别是在跨境网络环境下。如果你的翻译量不大且注重隐私,本地方案值得考虑。
想让聊天翻译真正"秒翻"?
OneChat一聊内置的AI翻译引擎采用了本地预处理+流式输出+翻译记忆库三层加速架构,在WhatsApp、Telegram、LINE等36+平台上实现即发即翻,首次响应延迟平均低于500ms。支持100+语言互译,所有翻译数据本地存储不外泄。不再需要在复制粘贴和等待加载中浪费时间。